Use Case
RUL-Prognose
Ziel des POC ist die Vorhersage der verbleibenden Nutzungsdauer von Turbofan-Triebwerken auf Basis von Betriebszyklen, Settings und Sensorsignalen. Der POC adressiert damit einen klassischen Predictive-Maintenance-Fall.
Diese Seite beschreibt den aufgebauten Predictive-Maintenance-Prototypen für Turbofan-Engines. Im Mittelpunkt stehen die NASA-C-MAPSS-Daten, die RUL-Prognose (Remaining Useful Life), die Modellwahl, die Bewertungsmethodik und der Vergleich aller vier Standard-Datensätze FD001 bis FD004.
Kompakte Einordnung des POC und der wichtigsten Ergebnisse.
Der POC basiert auf einem der bekanntesten Referenzdatensätze für Remaining-Useful-Life-Prognosen.
Die Daten beschreiben simulierte Turbofan-Triebwerke über viele Betriebszyklen. Jede Engine startet in einem gesunden Zustand und degradiert über die Zeit. Beobachtet werden pro Zyklus mehrere Betriebsparameter und Sensorsignale. Ziel ist die Schätzung der verbleibenden Lebensdauer bis zum Ausfall.
Die vier Standard-Subsets unterscheiden sich vor allem in der Zahl der Betriebsbedingungen und Fehlermodi. FD001 und FD003 sind typischerweise einfacher, FD002 und FD004 deutlich schwieriger. Dadurch eignen sie sich gut, um Robustheit und Generalisierbarkeit verschiedener Modelle zu vergleichen.
| Datensatz | Train Rows | Test Units | Features nach Engineering | Bestes Modell | Test RMSE | Test MAE |
|---|---|---|---|---|---|---|
| FD001 | 20,631 | 100 | 65 | HistGradientBoosting | 14.12 | 10.76 |
| FD002 | 53,759 | 259 | 89 | HistGradientBoosting | 26.92 | 19.05 |
| FD003 | 24,720 | 100 | 70 | HistGradientBoosting | 14.64 | 10.69 |
| FD004 | 61,249 | 248 | 89 | HistGradientBoosting | 28.09 | 20.78 |
Die Auswertung ist methodisch deutlich komplexer als ein einfacher Tabellen-Fit.
Für jedes Triebwerk wurde die Remaining Useful Life über die Zyklen berechnet. Für das Training wurde die Zielvariable auf 130 Zyklen gecappt, um extreme Frühphasenwerte zu stabilisieren und die Lernaufgabe praxisnäher zu machen.
Verwendet wurden Rohsensoren, Betriebssettings, log(time_cycles), cycle², erste Differenzen pro Engine, gleitende Mittelwerte über Fenster von 5 Zyklen sowie Abweichungen vom Startzustand je Sensor. Zusätzlich wurden konstante bzw. extrem varianzarme Signale entfernt.
Die Cross-Validation wurde nicht zufällig über Zeilen gemacht, sondern per GroupKFold nach Engine-ID. Dadurch landen Zyklen derselben Engine nie gleichzeitig in Train und Validation. Genau das ist für ehrliche PdM-Auswertung zentral.
Verglichen wurden Ridge Regression als lineare Baseline, Random Forest als robuste nichtlineare Baseline und HistGradientBoostingRegressor als starker, schneller Kandidat für tabellarische Zeitreihenfeatures.
Bewertet wurde über CV RMSE, CV MAE, Test RMSE, Test MAE und zusätzlich einen PHM-ähnlichen Score. Dadurch wird nicht nur die durchschnittliche Fehlergröße sichtbar, sondern auch die asymmetrische Bestrafung von Fehlprognosen.
Der POC ist bewusst eine beschleunigte Modellrunde. Es wurden keine tiefen neuronalen Architekturen und keine umfangreichen Hyperparameter-Suchen eingesetzt. Das Ziel war ein robuster, nachvollziehbarer und schnell kommunizierbarer Erstbenchmark.
Die folgenden Grafiken zeigen für jeden Datensatz dieselben zwei Perspektiven: Modellvergleich im Backtesting und Testprognosen auf Engine-Ebene.
FD001 ist der stärkste Datensatz im POC. HistGradientBoosting liegt klar vorn, was die Wahl als Standardmodell zusätzlich stützt.
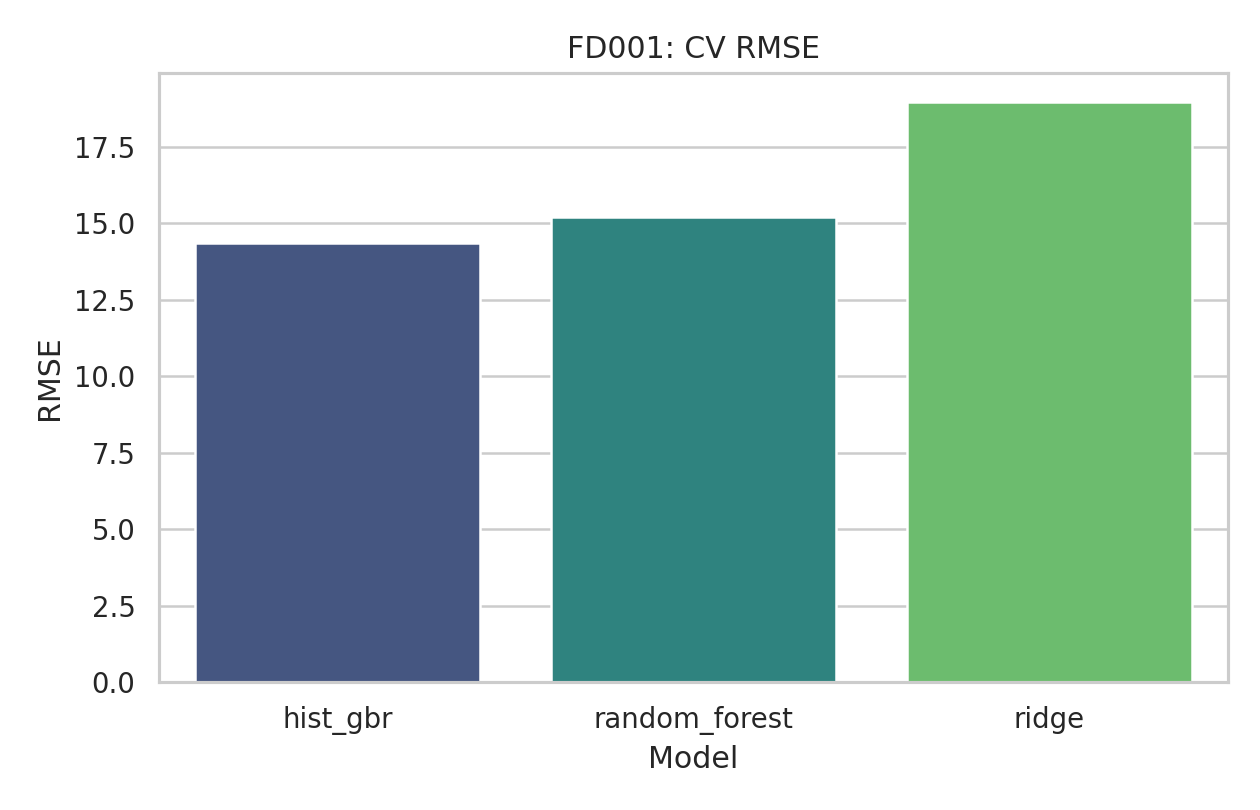
Die Vorhersagen liegen im gecappten Bereich relativ nah an der Diagonalen. FD001 bleibt damit der anschaulichste Fall für eine gut funktionierende RUL-Prognose.

Auch auf FD002 bleibt HistGradientBoosting vorn. Die Fehler sind aber bereits deutlich höher, was auf die gesteigerte Komplexität des Datensatzes hinweist.
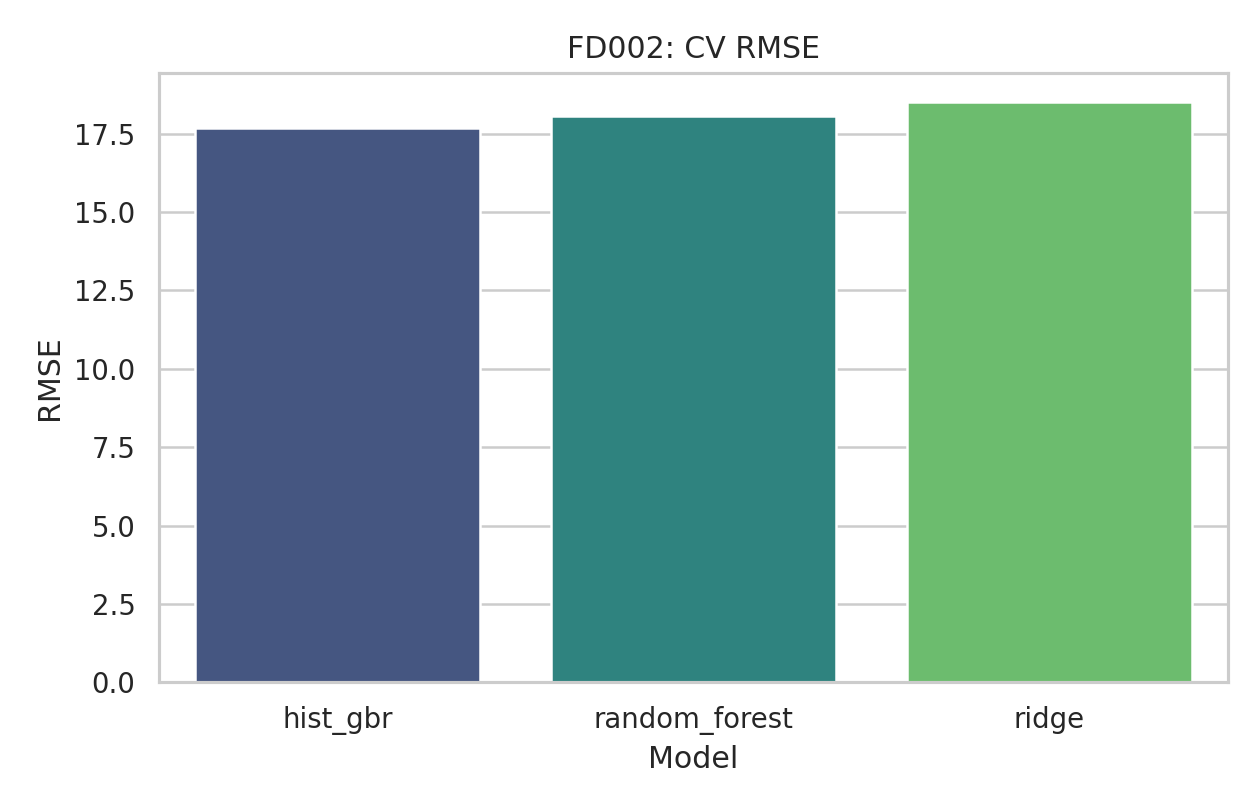
Auch nach Filterung auf Werte bis 130 bleibt die Streuung deutlich größer als bei FD001. Das zeigt die höhere Schwierigkeit bei mehreren Betriebsbedingungen und komplexeren Fehlermustern.

FD003 bestätigt den starken Eindruck eines vergleichsweise gut lösbaren Datensatzes. Die Modellwahl bleibt konsistent, und die Fehler liegen nahe bei FD001.
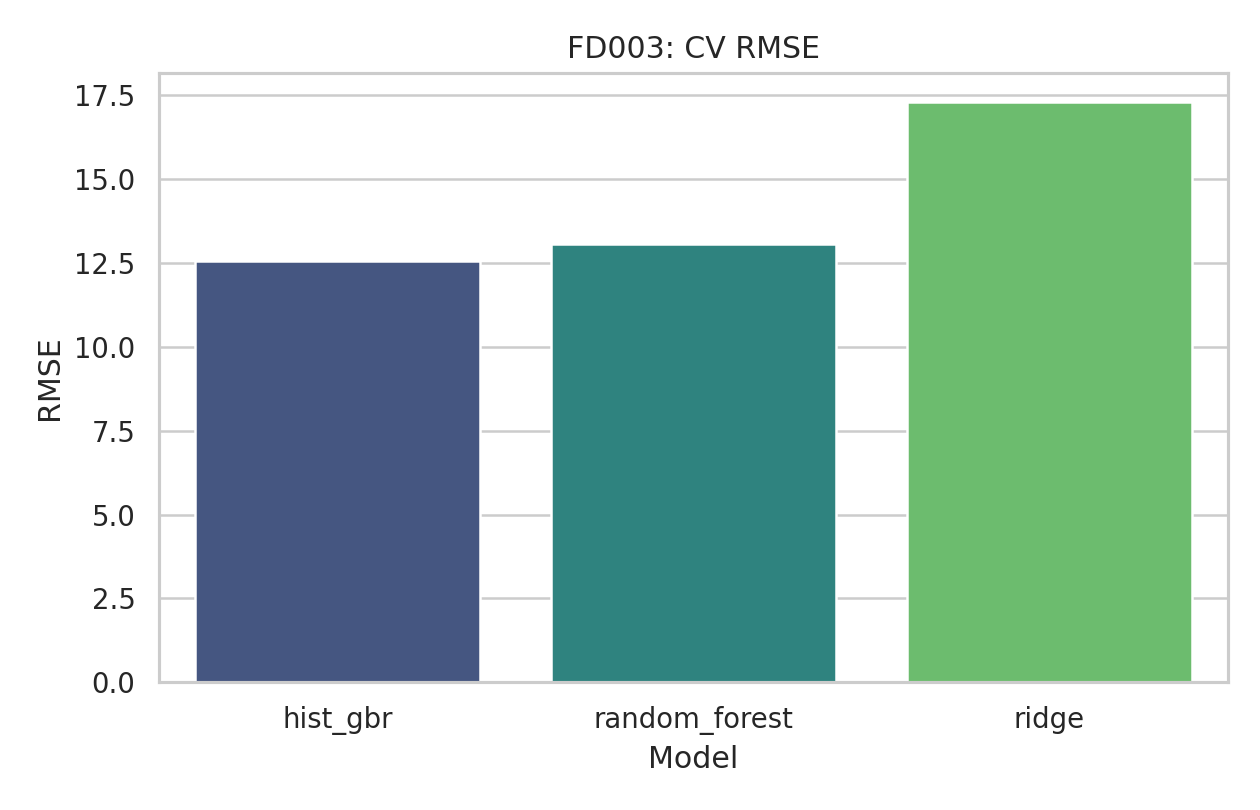
Auch im gefilterten Bereich bleiben die Testprognosen deutlich besser als auf FD002 und FD004. Das spricht für klarere Degradationsmuster und ein günstigeres Signal-Rausch-Verhältnis.

FD004 gehört zu den härtesten Fällen im gesamten Benchmark. HistGradientBoosting bleibt zwar bestes Modell, aber auf deutlich höherem Fehlerniveau.
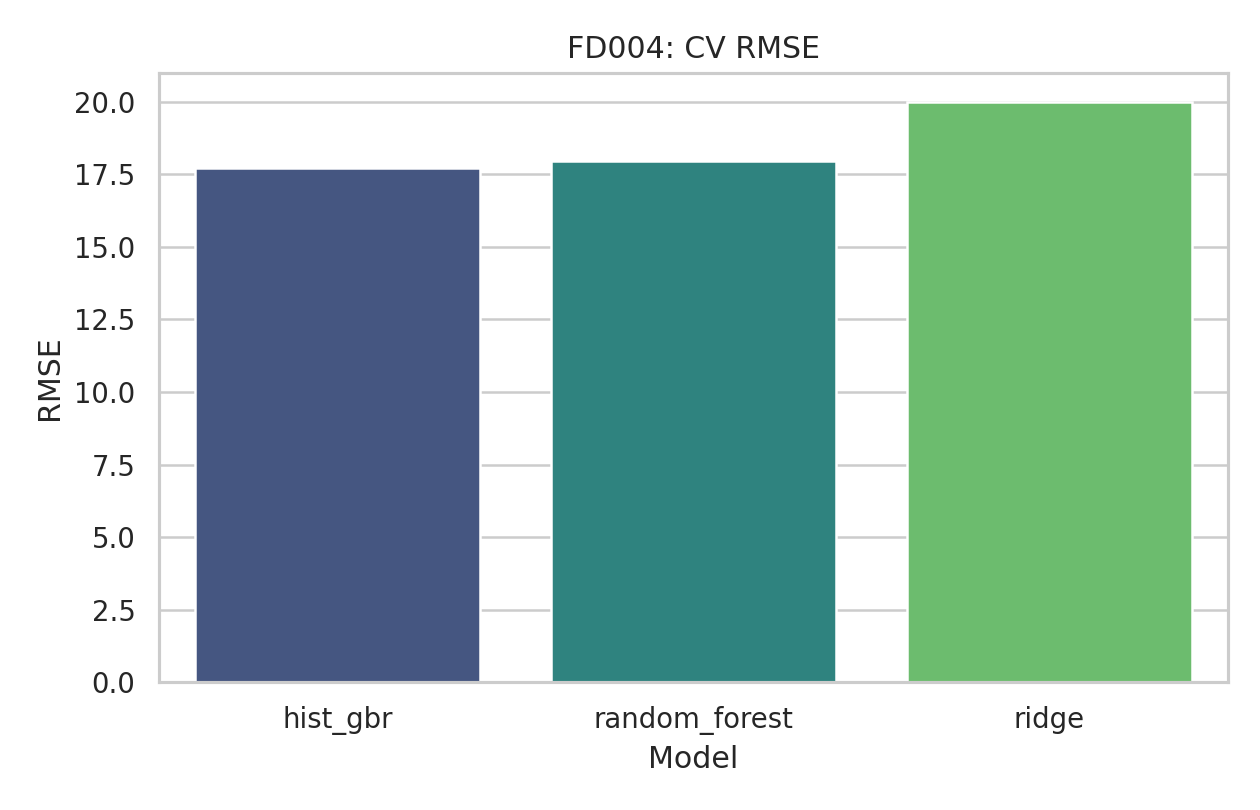
Die breite Streuung bleibt auch nach Filterung sichtbar und unterstreicht, wie herausfordernd FD004 ist. Der Datensatz zeigt klar, dass gute Resultate auf einfacheren Subsets nicht automatisch auf komplexere Szenarien übertragbar sind.

FD001 ist das beste Subset und eignet sich deshalb gut, um die interne Modelllogik sichtbar zu machen.
Die Feature-Importance-Ansicht für FD001 zeigt, dass die Prognose nicht auf einem einzelnen Sensor beruht. Das Modell nutzt mehrere kombinierte Signale aus Sensorik, Verlauf und Abweichung vom Startzustand.
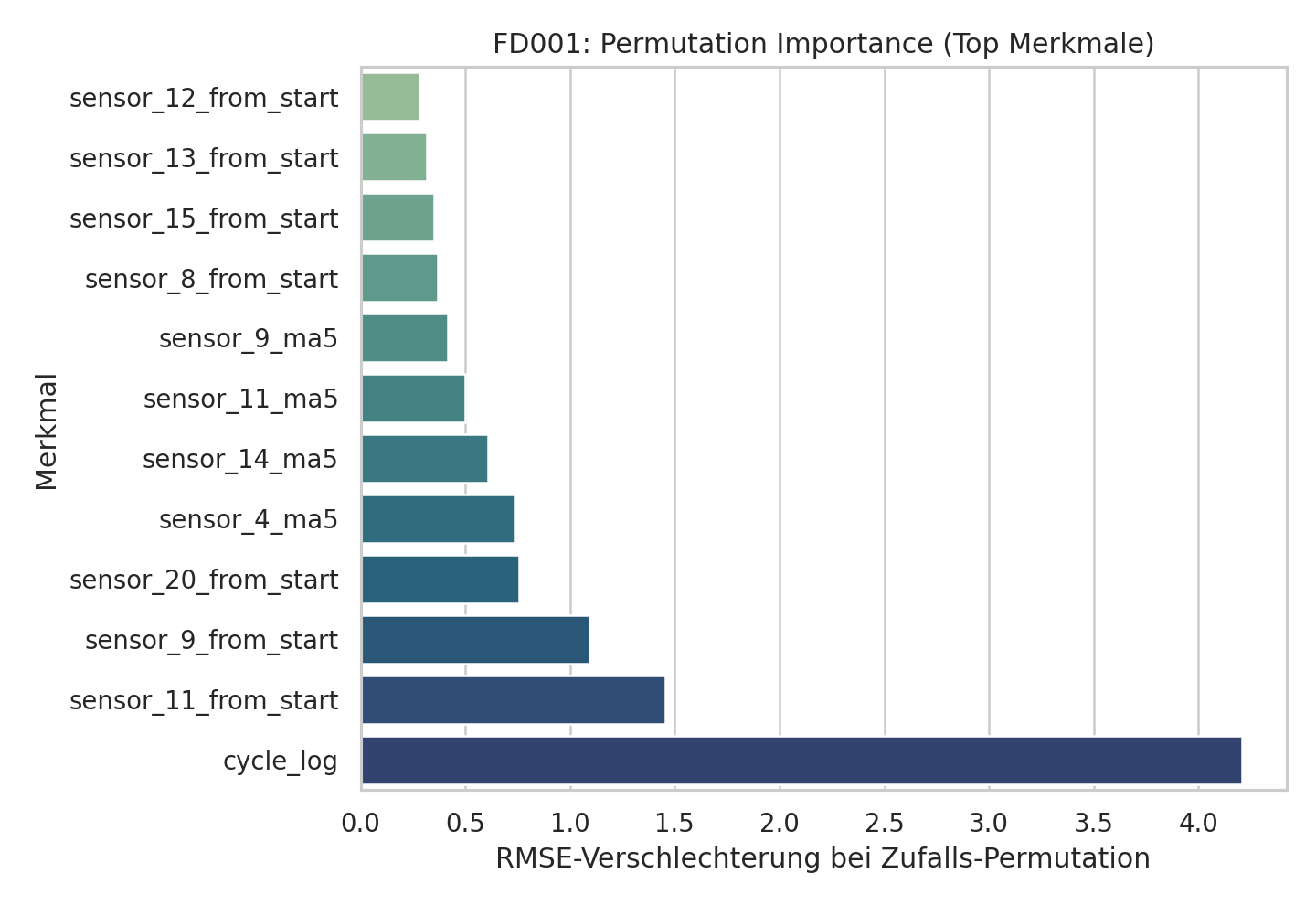
Genau hier wird die eigentliche Komplexität des POC sichtbar.
FD001 und FD003 verhalten sich deutlich günstiger als FD002 und FD004. Ein Modell, das auf einem „einfachen“ Subset gut aussieht, muss deshalb nicht automatisch auf komplexeren Szenarien überzeugen.
Trotz unterschiedlicher Datensatzschwierigkeit bleibt HistGradientBoosting auf allen vier Subsets das beste Modell der schnellen Runde. Das spricht für eine stabile, gut begründbare Startwahl im POC.
Die Vierdatensatz-Auswertung macht sichtbar, dass der POC nicht nur ein einzelnes gutes Beispiel zeigt, sondern das Problem über mehrere Schwierigkeitsgrade hinweg systematisch prüft.
Der POC wirkt auf den ersten Blick tabellarisch, ist methodisch aber deutlich anspruchsvoller.
Die Daten bestehen aus Verläufen pro Engine. Dadurch sind klassische zufällige Splits problematisch, weil dieselbe Engine über viele Zyklen Informationen über ihre Zukunft preisgibt. Saubere Auswertung muss assetbezogen denken.
Ein Modell, das auf FD001 sehr gut funktioniert, muss auf FD004 nicht annähernd dieselbe Qualität erreichen. Genau deshalb ist die Mehrdatensatz-Auswertung wichtig: Sie zeigt, wie robust ein Ansatz wirklich ist.
Nicht jeder Sensor trägt gleich viel Information. Manche Signale sind konstant, manche rauschen, manche werden erst in Kombination mit Differenzen, gleitenden Mitteln oder Verlaufsmustern nützlich. Das erklärt die starke Rolle des Feature Engineerings im POC.
Predictive Maintenance bewertet nicht nur Durchschnittsfehler. Zu frühe und zu späte Warnungen haben unterschiedliche operative Konsequenzen. Deshalb ist ein zusätzlicher PHM-orientierter Score sinnvoll.
Der POC prognostiziert keine einfache Ja/Nein-Störung, sondern eine verbleibende Nutzungsdauer in Zyklen. Das macht Interpretation, Fehlerkosten und Entscheidungslogik anspruchsvoller.
Für einen späteren produktionsnahen Einsatz wären zusätzliche Modellfamilien, Unsicherheitsabschätzung, Drift-Logik, Asset-spezifische Kalibrierung und Dashboard-/Alerting-Logik die nächsten sinnvollen Schritte.
Was aus der bisherigen Analyse belastbar abgeleitet werden kann.
Relevante Projektdateien und Ergebnisartefakte aus dem Workspace.
Wichtige lokale Projektpfade: